

摘要
随着科技的发展与进步,共享自动驾驶汽车将会是今后智能交通系统发展的方向之一。研究共享自动驾驶汽车的用户使用意愿,将有助于相关企业在未来的市场竞争中占据主动,以及更加便利的获取客源,提升用户体验。
本次调查研究针对共享自动驾驶的用户采纳度展开,通过焦点小组访谈和网络问卷调查的方式对TAM模型进行了扩展,并用结构方程进行拟合计算。
本次研究发现,共享自动驾驶汽车的可用性对使用意愿的影响很大;安全感、易用性、交通环境、付费意愿四者相互关联,并最终体现为付费意愿;而信任度并不对使用意愿产生直接显著的影响。
通过本次研究,为企业更好地发展共享自动驾驶汽车提供了建议与意见,也揭示了当下消费者对新鲜技术的开放心态。
关键词:TAM模型;结构方程;共享自动驾驶;感知可用性;
引言
随着科技的发展与进步,智能交通系统已经被应用于整个交通运输与管理体系中。在整车产品体验的工作与研究过程中,结合共享出行市场的蓬勃现状,我认为共享自动驾驶汽车将会是今后智能交通系统发展的方向之一。共享自动驾驶汽车通过使用自动驾驶功能代替司机,满足乘客打车出行需求,并且不受司机人力的影响,能够极大的提升道路交通出行的效率与实际体验。Apol来自百度旗下的自动驾驶出行服务平台Apollo GO,目前已在多个城市的自动驾驶示范区开展了试运营活动,这表明共享自动驾驶汽车在市场上已经收到了先锋企业的注意,并且政府也给予了极大的政策支持。而研究共享自动驾驶汽车的用户使用意愿,则有助于汽车厂商或相关自动驾驶功能的提供商在未来的市场竞争中占据主动,以及更加便利地获取客源,提升用户体验。
部分学者在公众对共享自动驾驶汽车使用意愿的研究上已经收获了一些成果,如Bansal等[1]发现超过80%的受访者认为共享自动驾驶服务收费不能超过当前打车或共享出行公司的收费水平。Fagnant等[2]研究表明,共享自动驾驶汽车对老年出行者以及无法自主开车的出行者更有吸引力。Pettigrew等[3]发现共享使用模式比私人拥有模式更受欢迎,能改善使用私人自动驾驶汽车的负面影响。
技术接受模型(Technology Acceptance Model, TAM)是Davis 在1989 年在基于理性行为理论的基础上进行推到探究的,通过信念-态度-意图-行为这一系列的因果关系来分析和验证系统外部变量对影响个人使用新的信息系统的原因。技术接受模型认为,一个人使用或接受新的信息系统的行为主要由个人的使用意愿决定,而个人使用新的信息系统的使用意愿又同时被个人对该系统的感知有用性和感知易用性所影响。感知易用性(Perceived ease-of-use,简称PEoU):用户在使用某一特定系统时,认为能为其省事减少用心费神的程度;感知有用性(Perceived usefulness,简称PU):用户在使用某一特定系统时,主观上认为其所带来的工作绩效的提升程度。用户的感知易用性越高,其使用态度倾向越积极。同时用户的感知易用性越高,其感知有用性也越大。
技术接受模型的构成如下图所示:
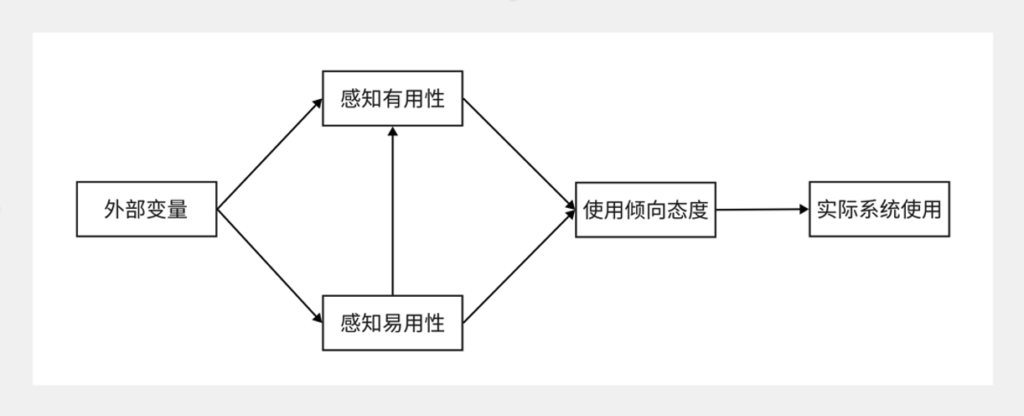
图1-1 技术接受模型(TAM)模型图
为了定量衡量用户对于共享自动驾驶汽车的使用意愿,本文将采用焦点小组访谈与网络调研两种调研方式。首先通过焦点小组访谈研究,对用户对共享自动驾驶的接受度与期望进行总结与洞察,并且识别出可能会影响用户采纳度的因素;接着通过网络问卷调查的形式(由于中国共享自动驾驶汽车市场投放极少,本次研究将通过Toluna问卷调研公司在美国加州进行问卷投放),收集用户反馈,在TAM模型的基础之上,再结合焦点小组访谈研究的结果进行扩展TAM模型的建模计算,最终挖掘出影响共享自动驾驶汽车用户采纳度的关键因素。
焦点小组访谈研究
焦点小组访谈研究的总体目标是了解每个参与者对自动驾驶技术的态度与担忧,从而为下一步的网络问卷的设计以及模型的建立提供指导。
调研对象及方法
本次焦点小组访谈总共分6个小组,每个小组包含6-12位参与人员,参与人员总数为60人,访谈地点为<涉密不披露>。6组成员按照不同特点进行分组,特点如下:
<涉密不披露>
访谈小组成员的招募具有随机性,并且因为资源与预算的限制,成员以<涉密不披露>为主,所以会代表一部分专家的观点,而与此相对的其他成员则以对自动驾驶技术不甚了解的人群为主,例如出租车司机人群与大学生人群。
访谈过程与焦点话题
访谈过程分为三个部分:1. 基本信息收集、2. 相关资料视频观看、3. 焦点话题交流。主要的内容如下:
- 基本信息收集:年龄、性别、教育程度、驾驶年限、年收入水平、自动驾驶使用经验等;
- 相关资料视频观看:自动驾驶分级的科普视频、自动驾驶的路试视频,此部分主要用于给予参访者必要的自动驾驶技术的相关知识;
- 焦点话题讨论:主要分为六个话题,主要的代表性问题如下:
- 自动驾驶技术采纳影响因素:“以下哪些因素在决策是否采用自动驾驶技术时产生影响?”
- 自动驾驶技术培训需求:“是否认为需要一定的培训才可以使用自动驾驶功能?“
- 政策激励:“是否认为需要政策推动自动驾驶功能的推广?”
- 风险与责任认定:“自动驾驶引起的事故由谁承担事故主体责任?”
- 数据隐私:“自动驾驶数据应该归谁所有?汽车厂商还是汽车拥有者?”
- 共享自动驾驶汽车:“对共享自动驾驶汽车有什么期望或好恶?”
访谈调研结果
访谈样本描述性统计
样本数据经过Excel透视表进行处理后,参与本次焦点小组访谈的人员的基本信息如下表所示:
| 变量名称 | 内容 | 样本数量 | 占比(百分比) |
| 性别 | 女 | 23 | 38.33% |
| 男 | 37 | 61.67% | |
| 年龄 | 18-29 | 34 | 56.67% |
| 30-44 | 23 | 38.33% | |
| 45-60 | 3 | 5.00% | |
| 学历 | 高中及以下 | 15 | 25.00% |
| 大专 | 7 | 11.67% | |
| 本科 | 26 | 43.33% | |
| 硕士研究生 | 11 | 18.33% | |
| 博士研究生及以上 | 1 | 1.67% | |
| 家庭年收入 | <10万 | 12 | 20.00% |
| 10万-20万 | 35 | 58.33% | |
| 20万-30万 | 6 | 10.00% | |
| 30万以上 | 7 | 11.67% | |
| 自动驾驶使用经验 | 有 | 29 | 48.33% |
| 无 | 31 | 51.67% |
| 变量名称 | 平均值 | 标准差 |
| 驾驶年数 | 5.22 | 5.21 |
从上述两表可以看出:
- 在接受调研的60位成员中,男女比例接近2:1,男士略多;
- 被调研的人群年龄主要分布在18-29岁之间,对新技术的参与度会高,但缺少购买意愿;其次占比最多的为30-44岁,这部分人群已有一定的工作经验,也相对务实,对于新技术既有参与又有可能进行付费购买;
- 接受访谈的人群的本科及以上学历占比最多,这表明访谈的结果相对可靠与真实;
- 从驾驶年限和自动驾驶使用经验上来看,本次访谈的人群主要分布在新手区和老手区,对自动驾驶功能的观点视角也会更加全面、丰富。
话题反馈描述性统计
经过六个话题的访谈与记录,将文言记录进行了筛选与分析,经过Excel透视表处理之后,访谈记录的统计如下表所示:
| 话题 | 提及次数 | 占比(百分比) |
| 自动驾驶技术采纳影响因素 | ||
| 技术的安全性 | 41 | 50.62% |
| 技术能带来的好处(便利/舒适/省时) | 19 | 23.46% |
| 技术能自适应驾驶员的驾驶习惯 | 10 | 12.35% |
| 来自驾驶员的信任 | 6 | 7.41% |
| 易用性 | 3 | 3.70% |
| 使用成本(订阅费用等) | 2 | 2.47% |
| 自动驾驶技术培训需求 | ||
| 1. 是否有需要进行自动驾驶技术的使用培训? | ||
| 有需要 | 37 | 61.67% |
| 不需要 | 23 | 38.33% |
| 2. 自动驾驶技术的使用培训是否应该强制? | ||
| 需要强制 | 13 | 35.14% |
| 不需要强制 | 24 | 64.86% |
| 政策激励 | ||
| 自动驾驶技术需要有政府进行激励 | 41 | 68.33% |
| 市场会自然的进行推广与演化,无需政府的干预 | 11 | 18.33% |
| 本身自动驾驶技术的便利性就有激励效果 | 5 | 8.33% |
| 说不好… | 3 | 5.00% |
| 风险与责任认定 | ||
| 1. 自动驾驶引起的事故由谁承担事故主体责任? | ||
| 汽车厂商 | 31 | 51.67% |
| 自动驾驶汽车车主(或使用者) | 21 | 35.00% |
| 汽车厂商和车主均有责任 | 7 | 11.67% |
| 自动驾驶技术程序员 | 1 | 1.67% |
| 数据隐私 | ||
| 1. 自动驾驶数据应该归谁所有?汽车厂商还是汽车拥有者? | ||
| 厂商和拥有者共有 | 23 | 56.10% |
| 汽车拥有者所有 | 15 | 36.59% |
| 厂商所有 | 3 | 7.32% |
| 2. 自动驾驶产生的数据可以商用吗? | ||
| 不可以进行任何形式的商业用途 | 13 | 61.90% |
| 仅可用于自动驾驶技术提升的商业用途 | 5 | 23.81% |
| 随便,并不在乎 | 3 | 14.29% |
| 共享自动驾驶汽车 | ||
| 1. 你觉得共享自动驾驶汽车可以提供哪些优势? | ||
| 舒适和整洁的乘车环境 | ||
| 更快更多的运营车辆供应 | ||
| 自定路线和上门服务 | ||
| 紧急情况下可以提供快速的响应服务 | ||
| 2. 当下是否会使用完全无人监管的共享自动驾驶汽车? | ||
| 会 | 15 | 31.25% |
| 不会 | 33 | 68.75% |
由上表可以看出:
- 大部分参与者都很关注自动驾驶的安全性,并且关注自动驾驶技术实际能够带来的便利性,而这两个观点在后续的访谈主题中也有相应的体现,表明安全和便利是用户采纳的主要关注点;
- 大多数参与者都觉得使用者应当接受培训后再使用自动驾驶技术,但是却不同意将自动驾驶技术培训作为强制培训,这表明大家并不愿意为了一项技术的推广而牺牲便利与私人时间;
- 绝大部分参与者都认为政府应当进行政策激励自动驾驶技术的市场推广,这体现出了大部分参与者对自动驾驶未来的不乐观,认为当前自动驾驶技术还没有展现出功能的可用性;
- 在自动驾驶相关的事故责任认定中,大部分参与者都认为厂商和车主应该是责任认定的焦点,但观点并无法统一,这表明归责问题将在具体的实践中对自动驾驶的推广产生影响,并可能会影响自动驾驶技术的用户采纳度;
- 数据隐私部分,绝大多数的人认为数据应当为车主所有,并且不同意任何形式的商业用途,这与实际的市场实践是相反的,这表明市场实践与用户的期望之间存在巨大的偏差;
- 最后,虽然参访者提供了许多自动驾驶为生活带来了各种便利性的观点,但是绝大多数参访者却表示在当下的阶段并不会使用自动驾驶技术,这表明前述反馈的期望与现实之间的偏差可能会是原因所在。
研究模型
概念模型
自动驾驶技术推出以来便备受市场关注,而共享自动驾驶汽车作为该技术下商业模式的一种创新,也非常适用技术接受模型(TAM)的研究。通过焦点小组的访谈结果,并且结合TAM传统模型,确定了本研究的基础模型,如下图所示:
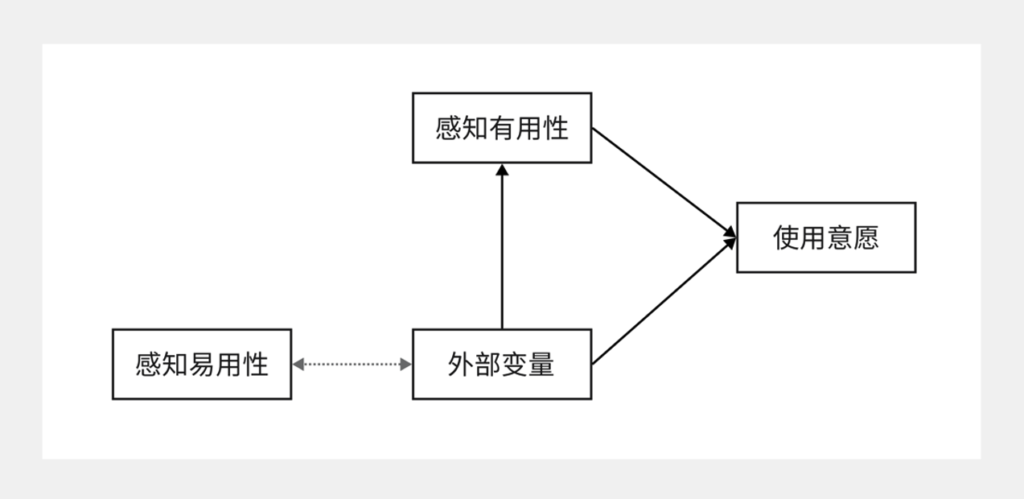
图4-1 共享自动驾驶汽车用户采纳模型
其中,外部变量代表着安全性、便利性等外部因素,在问卷设计部分会进一步进行详细描述。
问卷设计
调研问卷结构
本次调研采用了7分制的Likert 量表,被调研者将按照自身实际感受和态度去回答问题,量表中的答案为完全同意、同意、比较同意、一般、比较不同意、不同意、完全不同意这七种,这七个答案主要用于阐述被调研者对共享自动驾驶汽车相关话题的感受,分值对应为7、6、5、4、3、2、1 分。
问卷的测量指标
本研究的问卷量表设计中,首先具体根据共享自动驾驶汽车的功能、特性、范围以及焦点小组访谈的结果进行分析思考,针对的调研对象主要是已经使用过或有大量机会使用共享自动驾驶汽车的用户,并且对本次研究模型中的变量进行细化,形成问卷题目。同时也将被调研者者年龄、性别、学历等自身因素设计成题目,用于后续的数据分析。具体的变量与题目如下表所示:
| 变量 | 序号 | 问题描述 |
| 使用意愿 (BIU) | BIU1 | 假设我可以使用共享自动驾驶汽车,我打算使用它。 |
| BIU2 | 我希望将来能使用共享自动驾驶汽车。 | |
| BIU3 | 如果有共享自动驾驶汽车,我打算将来使用它。 | |
| 感知易用性 (PUoE) | PUoE1 | 学习使用共享自动驾驶汽车对我来说很容易。 |
| PUoE2 | 我很容易理解如何与共享自动驾驶汽车交互。 | |
| PUoE3 | 我将能够与共享自动驾驶汽车快速交互。 | |
| PUoE4 | 我很容易就能熟练使用共享自动驾驶汽车。 | |
| 感知有用性 (PU) | PU1 | 一个共享自动驾驶汽车对我经常去的地区很有用,比如停车位有限的市区。 |
| PU2 | 共享自动驾驶汽车会提高我在旅途中的工作效率(例如,有时间做一些工作)。 | |
| PU3 | 共享自动驾驶汽车将减少我的差旅费用。 | |
| PU4 | 共享自动驾驶汽车将最大限度地减少我在车辆维护和责任方面的责任。 | |
| PU5 | 我认为共享自动驾驶汽车可以在我需要的任何时候使用。 | |
| 信任 (TR) | TR1 | 共享自动驾驶汽车将不会出现错误或事故。 |
| TR2 | 一个共享自动驾驶汽车将能够在没有任何人为干预的情况下处理驾驶任务。 | |
| TR3 | 一个共享自动驾驶汽车将是可预测和可靠的。 | |
| TR4 | 我希望共享自动驾驶汽车能够提供充分、有效和响应迅速的帮助。 | |
| 扩展性 (CO) | CO1 | 共享自动驾驶汽车很适合我喜欢的交通方式。 |
| CO2 | 一个共享自动驾驶汽车会和我的私家车一样干净。 | |
| CO3 | 一个共享自动驾驶汽车将以我作为乘客所期望的方式驾驶。 | |
| 社会影响 (SI) | SI1 | 我的朋友/家人如果有共享自动驾驶汽车的经验,会鼓励我使用它。 |
| SI2 | 我会为成为共享自动驾驶汽车的用户而感到自豪。 | |
| SI3 | 如果我使用共享自动驾驶汽车,我将获得声望。 | |
| 安全 (SA) | SA1 | 如果我使用共享自动驾驶汽车服务,我会感到安全。 |
| SA2 | 在高度危险的情况下,共享自动驾驶汽车将保护乘客的生命和安全。 | |
| SA3 | 一个共享自动驾驶汽车将比司机更快地做出正确的决定和采取行动。 | |
| SA4 | 在危险的街区使用共享自动驾驶汽车会让我感到不安全。 | |
| 购买意愿 (WoP) | WoP1 | 一般来说,我愿意为共享自动驾驶汽车买单。 |
| WoP2 | 与共享乘车服务(滴滴打车)相比,我愿意为共享自动驾驶汽车支付更多费用。 | |
| WoP3 | 我愿意花钱使用共享自动驾驶汽车,因为它是一项尖端技术。 | |
| 交通环境 (TE) | TE1 | 我希望共享自动驾驶汽车能够应对在现实交通中遇到的激进司机。 |
| TE2 | 我希望共享自动驾驶汽车能够处理异常情况下的驾驶,例如施工或事故区域。 | |
| TE3 | 我希望共享自动驾驶汽车能够应对所有天气条件下的驾驶。 | |
| TE4 | 我希望共享自动驾驶汽车能够在维护不当的道路上行驶,如车道标记不清晰的地方。 |
结构方程
结构方程模型(Structural Equation Model)属于多变量统计分析的方法,是在变量的协方差矩阵的基础上,整合了因素分析和路径分析来分析多个变量之间关系的一种方法,也被称之为协方差结构分析。
本文将用Python进行SEM结构模型的建立,使用SEMOPY模组包进行分析,在判断结构方程的显著性时,可以按照下表所示的拟合度指标进行分析判断:
| 拟合度指标 | 指标结果要求 |
| CMIN/DF | 0<CMIN/DF<3,且越小越好 |
| GFI | 0.9<GFI<1,拟合度较好,0.7<GFI<0.9,拟合度可接受,GFI<0.7,拟合度不可接受 |
| RMR | 0<RMR<0.05,且越小越好 |
| RMSEA | 0<RMSEA<0.08,且越小越好 |
| CFI | 0.9<CFI<1,且越大越好 |
| IFI | 0.9<IFI<1,且越大越好 |
| AGFI | 0.9<AGFI<1,且越大越好 |
| NFI | 0.9<NFI<1,且越大越好 |
同时还需要通过路径系数的P值<0.05的显著性指标进行筛选判断。此外还需要验证标准化系数,即模型的系数估计值。
数据分析与结果讨论
本次网络问卷总共收集到513份回复,按照以下原则进行筛选与数据清洗:
- 未完成问卷结果需要删去;
- 年龄/驾驶年限等与实际明显不符合的需要删去。
筛选清洗后得到可用回复数量为226份,部分数据展示如下:
图5-1 网络问卷部分数据
将与Likert量表相对应的回答转换成数值,转换结果如下:
图5-2 经量表转换的部分回答
描述性统计
经过Excel透视表的处理后,参与本次问卷调查的对象基本信息如下表所示:
| 变量名称 | 内容 | 样本数量 | 占比(百分比) |
| 性别 | 女 | 133 | 58.85% |
| 男 | 93 | 41.15% | |
| 年龄 | 18-29 | 57 | 25.22% |
| 30-44 | 57 | 25.22% | |
| 45-60 | 66 | 29.20% | |
| > 60 | 46 | 20.35% | |
| 学历 | 高中 | 74 | 32.74% |
| 本科 | 96 | 42.48% | |
| 硕士 | 29 | 12.83% | |
| 博士 | 5 | 2.21% | |
| 博士后 | 7 | 3.10% | |
| 其他 | 15 | 6.64% | |
| 家庭年收入 | 小于16.25万元 | 34 | 15.04% |
| 16.25万元(含)-32.5万元(不含) | 62 | 27.43% | |
| 32.5万元(含)-48.75万元(不含) | 54 | 23.89% | |
| 48.75万元(含)-65万元(不含) | 32 | 14.16% | |
| 65万元(含)-81.25万元(不含) | 14 | 6.19% | |
| 81.25万元(含)-97.5万元(不含) | 9 | 3.98% | |
| 97.5万元(含)-113.75万元(不含) | 6 | 2.65% | |
| 113.75万元(含)-130万元(不含) | 3 | 1.33% | |
| 130万元及以上 | 12 | 5.31% | |
| 家庭拥车数 | 0 | 14 | 6.19% |
| 1 | 102 | 45.13% | |
| 2 | 83 | 36.73% | |
| 大于等于3 | 27 | 11.95% | |
| 电动车拥有量 | 0 | 194 | 85.84% |
| 1 | 25 | 11.06% | |
| 2 | 6 | 2.65% | |
| 大于等于3 | 1 | 0.44% | |
| 驾车通勤 | 是 | 199 | 88.05% |
| 否 | 27 | 11.95% | |
| 驾驶乐趣等级 | 非常享受驾驶 | 91 | 40.27% |
| 一般 | 111 | 49.12% | |
| 完全不享受驾驶 | 24 | 10.62% | |
| 新技术采纳度 | 早期采用者(最早采用新技术的) | 87 | 38.50% |
| 后期用户(等待一段时间的人) | 117 | 51.77% | |
| 落后者(最后采用新技术的) | 22 | 9.73% | |
| 环境保护关注度 | 很关注 | 138 | 61.06% |
| 一般关注 | 68 | 30.09% | |
| 完全不在意 | 20 | 8.85% | |
| 道路经历 | 高速公路 | 135 | 36.89% |
| 城市道路 | 75 | 20.49% | |
| 郊区道路 | 124 | 33.88% | |
| 乡村道路 | 32 | 8.74% |
| 变量名称 | 平均值 | 标准差 |
| 驾驶年数 | 24.41 | 17.37 |
| ADAS使用年数 | 2.15 | 3.69 |
| 通勤时间 | 2.25 | 2.99 |
| 堵车时间 | 1.25 | 2.77 |
从上表可以看出:
- 在接受调研的226份问卷统计中可以看出男女比例相对均衡;
- 被调研者的年龄分布也比较均衡,能比较全面地反映各个年龄段的看法与观点;
- 学历方面,参与问卷的人群主要为高中与本科学历,能够比较好的反映整个社会的情况;
- 收入方面,被调研人群的收入水平集中在16.25万元-48.75万元之间,是美国社会的平均水平;
- 绝大多数被调研者家庭拥有车辆,代表被调研人群有着基本的车辆使用经验;拥有电动车的家庭占比很少,这意味着大部分被调研者不具备自动驾驶技术的长期使用经验;
- 大部分人都驾车通勤,但是对驾驶的享受感分布比较均衡,说明问卷的调研不会因为享受驾驶或厌恶驾驶的情绪受到影响;
- 在新技术采纳情况上来看,绝对保守的落后者占比很少,而共享自动驾驶汽车在现阶段也应当更加关注早期用户的观点;
- 更值得注意的是,堵车时间在通勤时间中的占比达到50%,这也侧面体现出了整个社会的堵车水平。
样本信度分析
样本的信度分析,主要用于验证问卷掉后获得的结果是否具有一致性或者可靠性也就是说信度分析主要是用于判断被调研者是否真实地回答了问卷。信度,指的是数据的精确度,信度是通过在相同条件下,对一件事物经过测量了数次之后,其结果是否符合一定的规律,是否能够保持一致。如果得出的数据能够符合有一定的规律,没有较大偏差,则表示该测量结果具有一定可信度,并且,这些数据一致性的程度越高,则说明该测量结果可信度越高,即信度越高。
一般情况下信度分析结果通过Cronbach’s α信度系数来表示,Cronbach’s α系数值越大则表示数据的内在一致性越高。Cronbach’s α的具体要求如下表所示:
| 取值范围 | 取值标准含义 |
| 0.6<Cronbach’s α | 不可信 |
| 0.6≤Cronbach’s α<0.7 | 实务研究中可取 |
| 0.7≤Cronbach’s α<0.8 | 探索研究中可取 |
| 0.8≤Cronbach’s α | 基础研究中可取 |
本研究通过Python进行了信度分析,分析代码与注释如下:
| def cronbach_alpha(data): # 将数据转换成相关性矩阵 data_corr = data.corr() # 将数据的列数提取为变量N N = data.shape[1] # 将相关性矩阵相关性值加总并且平均值得出mean_r rs = np.array([ ]) for i, col in enumerate(data_corr.columns): sum_ = data_corr[col][i + 1:].values rs = np.append(sum_, rs) mean_r = np.mean(rs) # 使用公式进行计算:cronbach_alpha = (N * mean_r) / (1 + (N – 1) * mean_r) cronbach_alpha = (N * mean_r) / (1 + (N – 1) * mean_r) return cronbach_alpha |
经过计算,本次研究模型中的各变量的信度分析结果如下表所示:
| 变量 | 问题项 | 变量的Cronbach’s Alpha | 总体的Cronbach’s Alpha |
| 使用意愿 Behavioral Intention to Use (BIU) | BIU1 | 0.945 | 0.974 |
| BIU2 | |||
| BIU3 | |||
| 感知易用性 Perceived Ease of Use (PUoE) | PUoE1 | 0.900 | |
| PUoE2 | |||
| PUoE3 | |||
| PUoE4 | |||
| 感知有用性 Perceived Usefulness (PU) | PU1 | 0.835 | |
| PU2 | |||
| PU3 | |||
| PU4 | |||
| PU5 | |||
| 信任度 Trust (TR) | TR1 | 0.876 | |
| TR2 | |||
| TR3 | |||
| TR4 | |||
| 扩展性 Compatibility (CO) | CO1 | 0.795 | |
| CO2 | |||
| CO3 | |||
| 社交影响 Social Influence (SI) | SI1 | 0.872 | |
| SI2 | |||
| SI3 | |||
| 安全感 Safety (SA) | SA1 | 0.625 | |
| SA2 | |||
| SA3 | |||
| SA4 | |||
| 付费意愿 Willingness to Pay (WoP) | WoP1 | 0.910 | |
| WoP2 | |||
| WoP3 | |||
| 交通环境 Traffic Environment (TE) | TE1 | 0.922 | |
| TE2 | |||
| TE3 | |||
| TE4 |
从信度检测结果来看每个变量对应的问题结果的Cronbach’s α除SA问题项外都大于 0.75,且总体数据的Cronbach’s α大于0.9,说明问卷数据具有较高的可信度,可以用于进行下一步的研究分析。
样本效度分析
为检验数据的效度,使用Python进行编程分析,效度检验结果如下表所示:
| 变量 | 问题项 | KMO值 | 因子载荷 | 方差累计贡献率 |
| 使用意愿 Behavioral Intention to Use (BIU) | BIU1 | 0.768 | 0.879 | 99.786% |
| BIU2 | 0.857 | |||
| BIU3 | 0.896 | |||
| 感知易用性 Perceived Ease of Use (PUoE) | PUoE1 | 0.833 | 0.810 | |
| PUoE2 | 0.850 | |||
| PUoE3 | 0.826 | |||
| PUoE4 | 0.824 | |||
| 感知有用性 Perceived Usefulness (PU) | PU1 | 0.832 | 0.821 | |
| PU2 | 0.798 | |||
| PU3 | 0.868 | |||
| PU4 | 0.939 | |||
| PU5 | 0.912 | |||
| 信任度 Trust (TR) | TR1 | 0.828 | 0.830 | |
| TR2 | 0.848 | |||
| TR3 | 0.796 | |||
| TR4 | 0.806 | |||
| 扩展性 Compatibility (CO) | CO1 | 0.695 | 0.834 | |
| CO2 | 0.936 | |||
| CO3 | 0.827 | |||
| 社交影响 Social Influence (SI) | SI1 | 0.731 | 0.819 | |
| SI2 | 0.867 | |||
| SI3 | 0.831 | |||
| 安全感 Safety (SA) | SA1 | 0.725 | 0.861 | |
| SA2 | 0.823 | |||
| SA3 | 0.786 | |||
| SA4 | 0.976 | |||
| 付费意愿 Willingness to Pay (WoP) | WoP1 | 0.752 | 0.868 | |
| WoP2 | 0.882 | |||
| WoP3 | 0.859 | |||
| 交通环境 Traffic Environment (TE) | TE1 | 0.836 | 0.840 | |
| TE2 | 0.857 | |||
| TE3 | 0.843 | |||
| TE4 | 0.867 |
每个变量的KMO值均大于0.6,可以进行因子分析。通过因子分析检验效度,从样本数据中提取12个因子,方差累积贡献率达99.786%,且各项的因子载荷指数均大于0.7.即对成分解释度较好,收敛效度好。
样本相关分析
相关分析主要是为了发现模型中各变量之间的相关特性,分析变量之间是否呈线性相关关系,以及他们之间相关程度。而相关分析中使用相关系数来表示变量之间的密切程度,相关系数r 介于-1 到1 之间,如果相关系数大于0 时,表示变量之间呈现正相关,如果相关系数小于0,则表示变量之间为负相关。如果相关系数r 越接近1 或者-1,则表示变量之间的关联性越强,如果相关系数越接近0,则表示变量之间的相关性越弱。
本次研究主要使用Python先进行Pearson相关性分析,各变量的相关分析结果如下表所示:
| BIU | PUoE | PU | TR | CO | SI | SA | WoP | TE | |
| BIU | 1.000 | 0.567 | 0.772 | 0.708 | 0.717 | 0.837 | 0.701 | 0.824 | 0.734 |
| PUoE | 0.567 | 1.000 | 0.701 | 0.666 | 0.693 | 0.606 | 0.615 | 0.567 | 0.626 |
| PU | 0.772 | 0.701 | 1.000 | 0.772 | 0.781 | 0.815 | 0.718 | 0.760 | 0.719 |
| TR | 0.708 | 0.666 | 0.772 | 1.000 | 0.799 | 0.764 | 0.741 | 0.739 | 0.778 |
| CO | 0.717 | 0.693 | 0.781 | 0.799 | 1.000 | 0.810 | 0.689 | 0.747 | 0.721 |
| SI | 0.837 | 0.606 | 0.815 | 0.764 | 0.810 | 1.000 | 0.774 | 0.857 | 0.728 |
| SA | 0.701 | 0.615 | 0.718 | 0.741 | 0.689 | 0.774 | 1.000 | 0.752 | 0.700 |
| WoP | 0.824 | 0.567 | 0.760 | 0.739 | 0.747 | 0.857 | 0.752 | 1.000 | 0.720 |
| TE | 0.734 | 0.626 | 0.719 | 0.778 | 0.721 | 0.728 | 0.700 | 0.720 | 1.000 |
由上表中挑选相关系数0.77以上的组合,可以挑选出以下正相关关系:
- 使用意愿与感知有用性、社交影响、付费意愿的正相关关系;
- 感知有用性与信任度、扩展性、社交影响的正相关关系;
- 信任度与扩展性、交通环境的正相关关系;
- 扩展性与社交影响的正相关关系;
- 社交影响与安全感、付费意愿的正相关关系;
结构方程分析
在Python中使用SEMOPY模块包进行结构方程分析,分析代码与注释如下:
| def SEM_Construction(data): desc = ”’ # 变量计算关系 BIU =~ BIU1 + BIU2 + BIU3 PUoE =~ PUoE1 + PUoE2 + PUoE3 + PUoE4 PU =~ PU1 + PU2 + PU3 + PU4 + PU5 TR =~ TR1 + TR2 + TR3 + TR4 CO =~ CO1 + CO2 + CO3 SI =~ SI1 + SI2 + SI3 SA =~ SA1 + SA2 + SA3 + SA4 WoP =~ WoP1 + WoP2 + WoP3 TE =~ TE1 + TE2 + TE3 + TE4 # 变量回归关系 BIU ~ PU + SI + WoP PUoE ~ PU PU ~ TR + CO + SI TR ~ CO + TE CO ~ SI SI ~ SA + WoP ”’ mod = sem.Model(desc) #将结构方程描述赋予SEM模型 res = mod.fit(data) #将数据匹配进SEM模型 ins = mod.inspect() #输出路径系数估计值、标准误差、Z值、P值 sem.report(mod, “Shared ADAS”) #保存结果至HTML文件 |
得出结构方程模型路径关系如下表:
| 变量之间的路径关系 | 路径系数估计值 | 标准误差 | z值 | p值 | 显著性 | ||
| BIU | <– | PU | 0.313 | 0.188 | 1.664 | 0.095 | 不显著 |
| BIU | <– | SI | 0.412 | 0.347 | 1.187 | 0.235 | 不显著 |
| BIU | <– | WoP | 0.374 | 0.171 | 2.179 | 0.029 | 显著 |
| PU | <– | TR | 0.202 | 0.121 | 1.665 | 0.095 | 不显著 |
| PU | <– | CO | -0.249 | 0.412 | -0.604 | 0.545 | 不显著 |
| PU | <– | SI | 1.183 | 0.540 | 2.191 | 0.028 | 显著 |
| TR | <– | CO | 0.483 | 0.072 | 6.686 | 0 | 显著 |
| TR | <– | TE | 0.358 | 0.071 | 5.020 | 0 | 显著 |
| CO | <– | SI | 1.325 | 0.087 | 15.145 | 0 | 显著 |
| SI | <– | SA | 0.343 | 0.088 | 3.891 | 0 | 显著 |
| SI | <– | WoP | 0.397 | 0.076 | 5.229 | 0 | 显著 |
按照P<0.05的显著性要求进行筛选,将显著性不明显的BIUSI和PUCO的关系去除,再次求得结构方程模型路径关系表如下:
| 变量之间的路径关系 | 路径系数估计值 | 标准误差 | z值 | p值 | 显著性 | ||
| BIU | <– | PU | 0.460 | 0.140 | 3.282 | 0 | 显著 |
| BIU | <– | WoP | 0.550 | 0.110 | 5.017 | 0 | 显著 |
| PU | <– | TR | 0.160 | 0.114 | 1.399 | 0.162 | 不显著 |
| PU | <– | SI | 0.896 | 0.142 | 6.313 | 0 | 显著 |
| TR | <– | CO | 0.489 | 0.073 | 6.711 | 0 | 显著 |
| TR | <– | TE | 0.355 | 0.072 | 4.961 | 0 | 显著 |
| CO | <– | SI | 1.321 | 0.087 | 15.107 | 0 | 显著 |
| SI | <– | SA | 0.331 | 0.090 | 3.695 | 0 | 显著 |
| SI | <– | WoP | 0.409 | 0.078 | 5.264 | 0 | 显著 |
再次按照P<0.05的显著性要求进行筛选,将显著性不明显的PUTR的关系去除,再次求得结构方程模型路径关系表如下:
| 变量之间的路径关系 | 路径系数估计值 | 标准误差 | z值 | p值 | 显著性 | ||
| 使用意愿 BIU | <– | 感知可用性 PU | 0.492 | 0.143 | 3.438 | 0 | 显著 |
| 使用意愿 BIU | <– | 付费意愿 WoP | 0.525 | 0.112 | 4.701 | 0 | 显著 |
| 感知可用性 PU | <– | 社交影响 SI | 1.067 | 0.081 | 13.172 | 0 | 显著 |
| 信任度 TR | <– | 扩展性 CO | 0.519 | 0.075 | 6.940 | 0 | 显著 |
| 信任度 TR | <– | 交通环境 TE | 0.327 | 0.072 | 4.547 | 0 | 显著 |
| 扩展性 CO | <– | 社交影响 SI | 1.317 | 0.087 | 15.136 | 0 | 显著 |
| 社交影响 SI | <– | 安全感 SA | 0.388 | 0.091 | 4.270 | 0 | 显著 |
| 社交影响 SI | <– | 付费意愿 WoP | 0.363 | 0.077 | 4.726 | 0 | 显著 |
同时结构方程的拟合评估数据也符合模型评估需求:
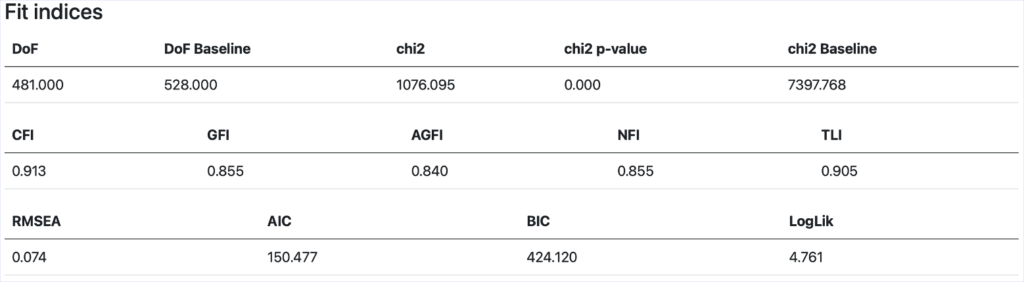
图5-3 结构方程拟合度验证结果
按照上述具有显著性的路径关系表可以各变量之间的路径关系图如下:

图5-4 结构方程分析结果与各变量路径关系图
通过以上数据可以得出基于扩展TAM模型的共享自动驾驶用户采纳模型中各变量之间的关系可以用下图表示:
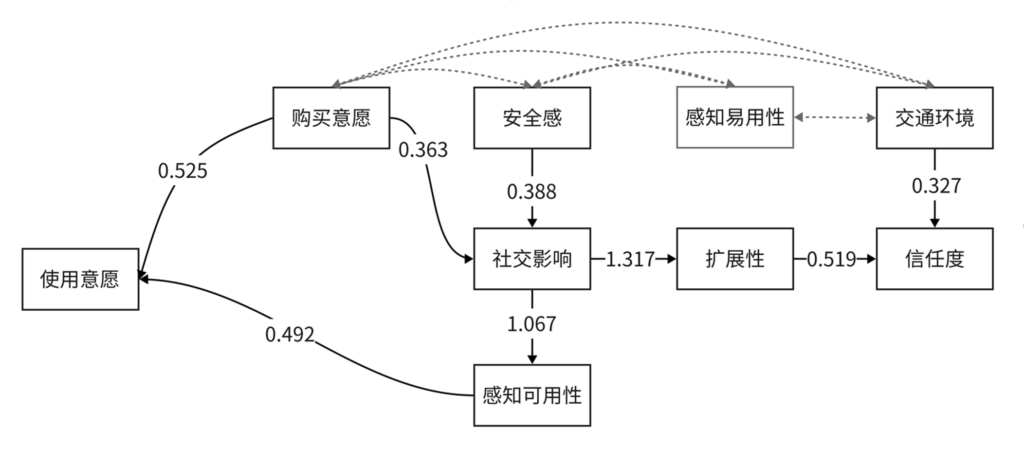
图5-5 模型间各变量关系图
由上图可以看出:
- 安全感与购买意愿可以通过社交影响这个变量来影响感知可用性,从而对使用意愿产生影响。换言之感知可用性除了大众对于功能的自我认知外,还会受到社交因素的影响。并且购买意愿和安全感的评价会对社交评价产生影响。
- 购买意愿对使用意愿的影响是所有外部变量中最直接的影响因素,而购买意愿、安全感、感知易用性、交通环境之间存在相互影响的关系,无法分析单向的传递关系;
- 信任度和扩展性从拟合结果上来看并不会对使用意愿产生影响。
结论与观点
从上述分析中可以看出:
- 从企业的角度而言,共享自动驾驶汽车的可用性越高,消费者的使用意愿越强烈。这意味着,企业需要在硬件性能和功能可用性上提升共享自动驾驶汽车的用户体验,让共享自动驾驶汽车使用过程中的每个环节都能完整流畅;
- 除了硬性条件上的可用性之外,企业也应当注重品牌的社交营销活动,通过消费者的口口相传,建立消费者对品牌的认可,从而让消费者心理上认可共享自动驾驶汽车;
- 一般来说消费者的购买行为直接体现了使用意愿,但是购买行为背后则是安全感、易用性、交通环境因素的相互作用。所以一方面企业要切实提升共享自动驾驶汽车的安全性与使用的便利性,另一方面也要依赖于社会整体的交通环境,只有在一个合适的交通环境中,共享自动驾驶汽车才能有良好的发展;
- 与常识不同的是,信任度并不直接对使用意愿产生影响,换言之,消费者自身信不信任共享自动驾驶汽车并不影响使用行为的建立。这个结果可以表明消费者对于新技术风险的接受度是存在的,这一现象可能也与当前社会的新科技萌发速度快有关,导致消费者对于新鲜事物的心态较为积极。
参考文献
- BANSAL P, KOCKELMAN K M, SINGH A. Assessing public opinions of and interest in new vehicle technologies: an Austin perspective[J]. Transportation Research Part C: Emerging Technologies, 2016, 67: 1-14.
- FAGNANT D J, KOCKELMAN K. The travel and environmental implications of shared autonomous vehicles, using agent—based model scenarios[J]. Transportation Research Part C: Emerging Technologies, 2014, 40: 1—13.
- PETTIGREW S, DANA L M, NORMAN R. Clusters of potential autonomous vehicles users according to propensity to use individual versus shared vehicles[J]. Transport Policy, 2019, 76: 13—20.
- 许碧怡. 基于扩展TAM 模型的企业微信用户采纳研究[D]. 华南理工大学, 2020.
- 胡晓伟, 石腾跃, 于璐, 毛科俊. 基于扩展技术接受度模型的共享自动驾驶汽车用户使用意愿研究[J]. 交通运输工程与信息学报, 2021.